循环神经网络(Rerrent Neural Network, RNN)
传统的神经网络在处理上一条数据和下一条数据时不会进行交流,换言之,模型并不会记得上一条它处理的数据是什么,有什么特点。这种特性在处理图片时问题不大,前一张图片和后一张图片之间并没有什么序列特性。
但如果是一句话、一段音频、或者一段视频的时候,这些数据里面往往都含有时间上的关联,也即时序信息。这个时候就需要循环神经网络 RNN 来处理。”RNN 对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,利用了 RNN 的这种能力,使深度学习模型在解决语音识别、语言模型、机器翻译以及时序分析等 NLP 领域的问题时有所突破。”[1]
一个词语在不同的句子上下文里会有不同的意义,比如 miss 这个词,可以是“错过”,也可以是“想念”,不同的语境里意义完全不同,正如 [1] 中所描述的那样,假如我们有一堆已经翻译好的英文句子,英文句子作为样本,翻译作为标签,供模型训练,如果使用神经网络去做翻译这个事,当它学习 miss 时可能就会犯迷糊,因为喂给模型的 miss 里有些标签是“错过”,有些标签是“想念”,模型对 miss 的翻译就取决于哪种标签占多数。这种模型训练出来得到的性能自然不会很好。
但循环神经网络就不一样了,从循环神经网络的名字上来看,“循环”两个字就是这个网络的核心,网络内部有循环,模型处理完上一个数据后,内部的状态会保留下来,参与到下一个数据的处理中去。\(x\) 是输入,\(h_t\) 是隐藏层输出,\(A\) 相当于隐藏层的权重矩阵。
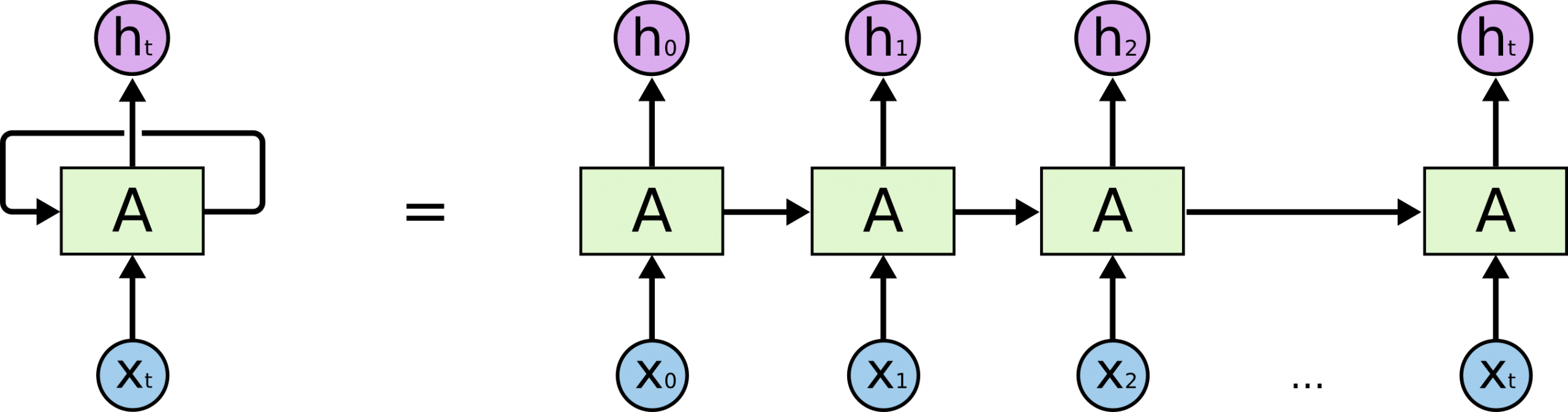
从上图可以看出,\(h_1\) 是 \(x_1\) 和上一个时刻的 \(A\) 做输入,经隐藏层处理后的输出。此时 \(h_1\) 里既有 \(x_0\) 的信息(部分保留在上一个时刻的 \(A\) 中)又有 \(x_1\) 的信息,RNN 就具备了获取上文信息的能力。而且如果交换 \(x_0\) 和 \(x_1\) ,得到的 \(h_1\) 也会完全不同,模型对序列也变得更敏感。
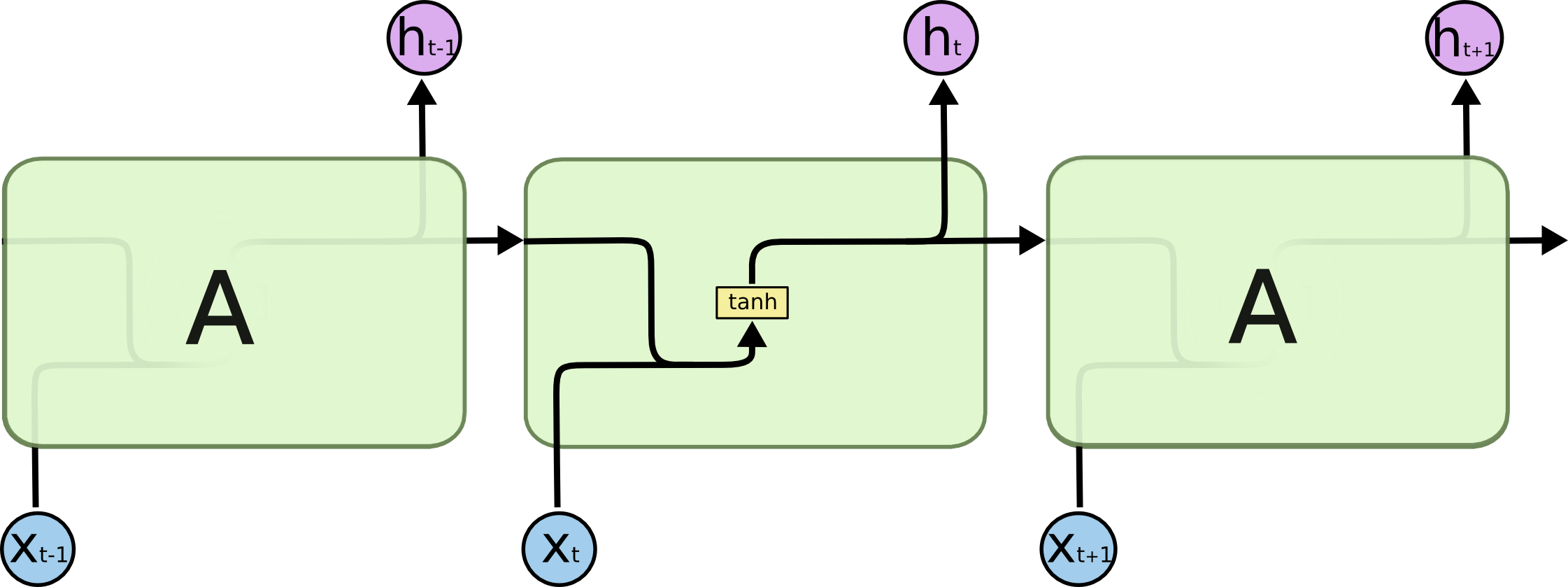
标准的 RNN 一个模块内部仅有一个神经网络层(黄色块),激活函数为 tanh,然后由一串重复的神经网络模块组成。RNN 的缺点很明显,每次它都只是用上一个时刻的状态,更多时候我们需要更长的上下文,理论上 RNN 可以做到处理长期依赖关系,毕竟 \(A\) 是一路往后传过去的,但在实践中 RNN 没办法做到,处理完新的数据后,当下梯度更新时,和当前距离过长的远古信息就会“衰减”,就是说前面的梯度会消失,梯度消失了就没办法用上了。
所幸人们又提出了长短期记忆网络,改善了 RNN 的诸多不便。
长短期记忆网络(Long Short Term Memory networks, LSTM)
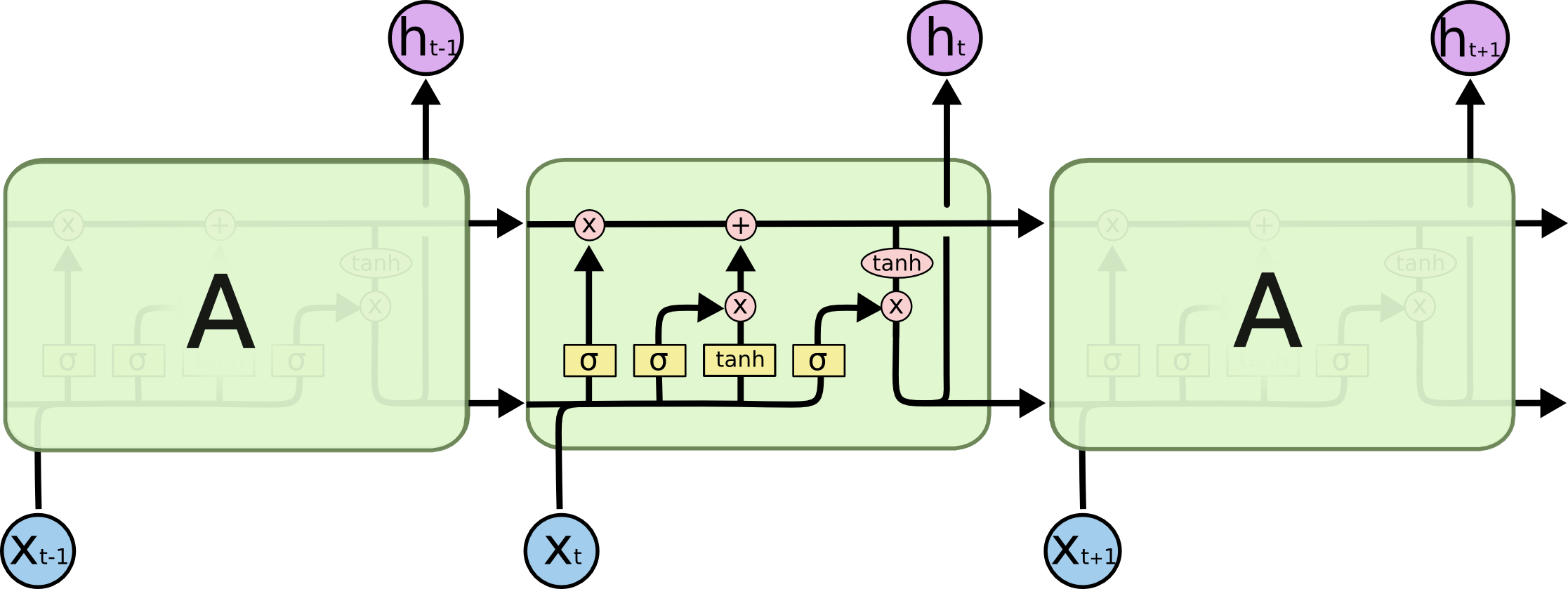

LSTM 也是这种链式结构,但是每个模块里面有四个神经网络层。分别担当三个门的工作。分别是遗忘门(Forget Gate)、输入门(Input Gate)和输出门(Output Gate)。模块内最上方那条直线相当于记忆流水线(记忆细胞),在三个门的影响下更新其中的记忆。
遗忘门(Input Gate)
用来决定从记忆中丢掉哪些信息。
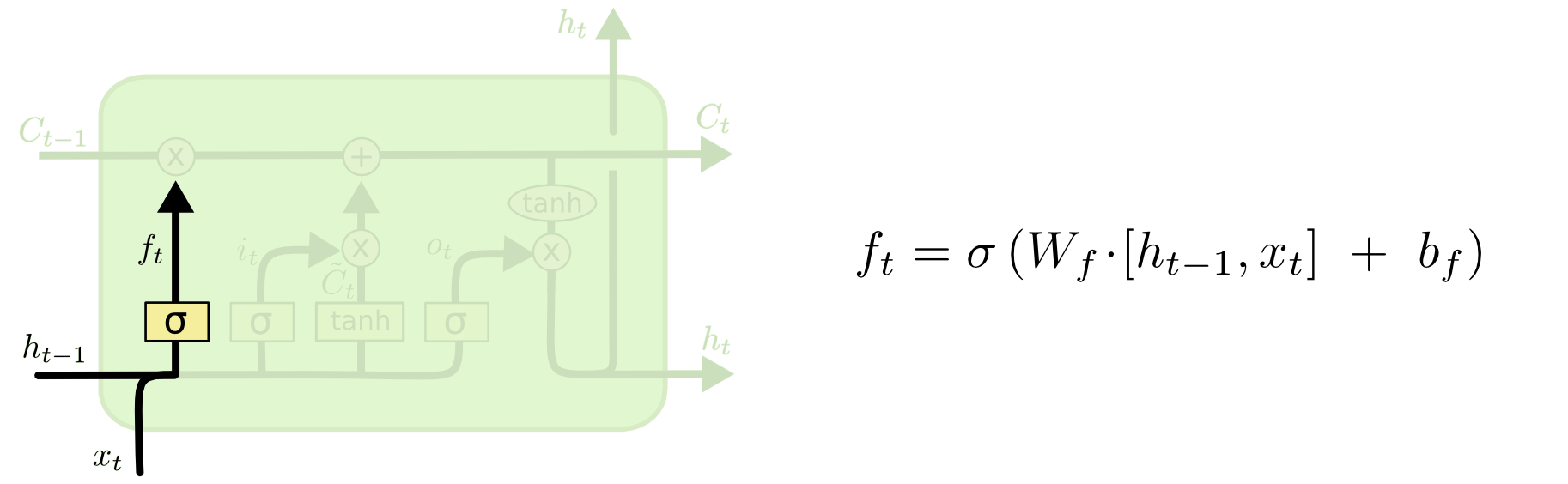
记忆就相当于一个仓库(矩阵)里的很多货物(元素),遗忘门就相当于清理工,对每一个货物进行检查,决定哪些该留下、哪些该扔掉。上一时刻的记忆 \( C_{t-1} \) 输入进来,与 \( f_t \) 做逐元素相乘,达成遗忘的目的。
\( f_t \) 又由上一时刻的隐藏层输出 \( h_{t-1} \) 和这一时刻的输入 \( x_{t} \) 共同决定,拼接后经过一个 Sigmoid 激活的神经网络层,因为 Sigmoid 会将值压缩在 0 到 1 之间,类似门控信号,这样就做到了“清理”,1 就完全保留,0 就完全丢弃。
输入门(Input Gate)
用来决定往记忆中存储哪些新信息。
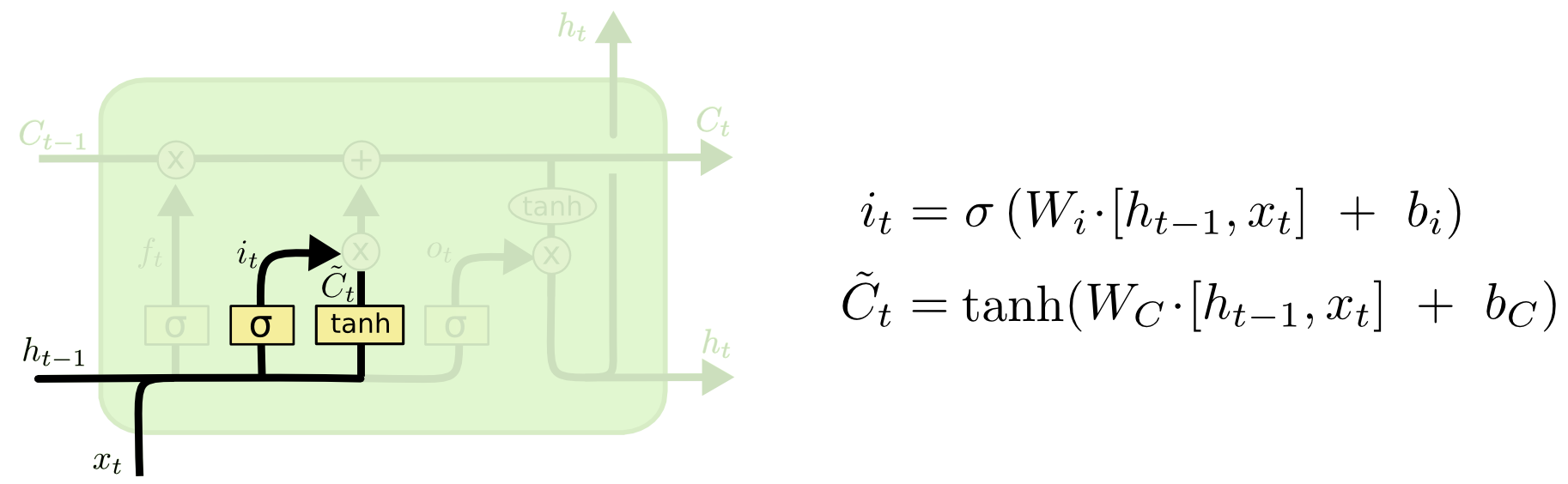
记忆仓库得到了清理,现在开始往里面存新的货物(元素相加)。但是存新货物之前,需要“审核员”这个输入门来对货物的质量进行“把关”(PS:这也是 RNN 不具备的特点,RNN 是对所有输入全盘接收),将 \( \tilde{C}_t \) 和 \( i_{t} \) 相乘,得到“审核”后的货物,再和清理后的记忆相加,达成输入的目的。
\( i_{t} \) 同样是由上一时刻的隐藏层输出 \( h_{t-1} \) 和这一时刻的输入 \( x_{t} \) 共同决定,同样经过一个 Sigmoid 激活的神经网络层,也相当于门控,只不过是对输入的门控。
\( \tilde{C}_t \) 的输入也是一样的,唯一有区别的地方就是经过的神经网络层,其激活函数是 tanh。
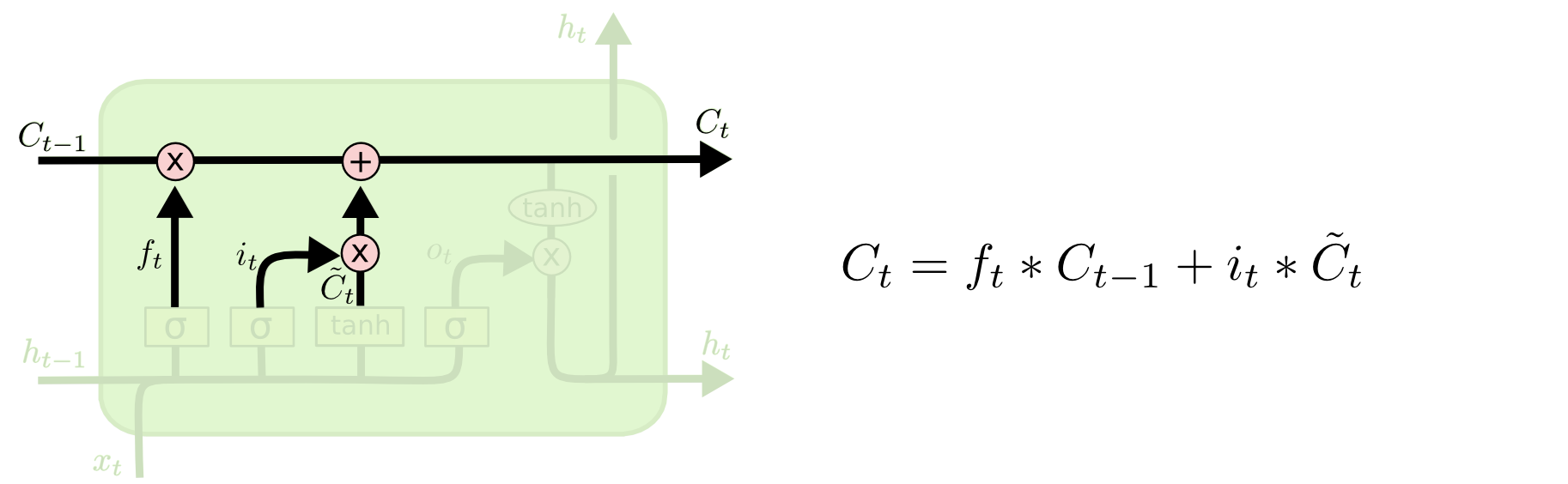
经过了遗忘门和输入门,当前就不会再动记忆仓库里的东西(如上图所示),而是考虑如何从记忆仓库里取东西。
输出门(Output Gate)
用来决定从记忆中取出哪些信息。
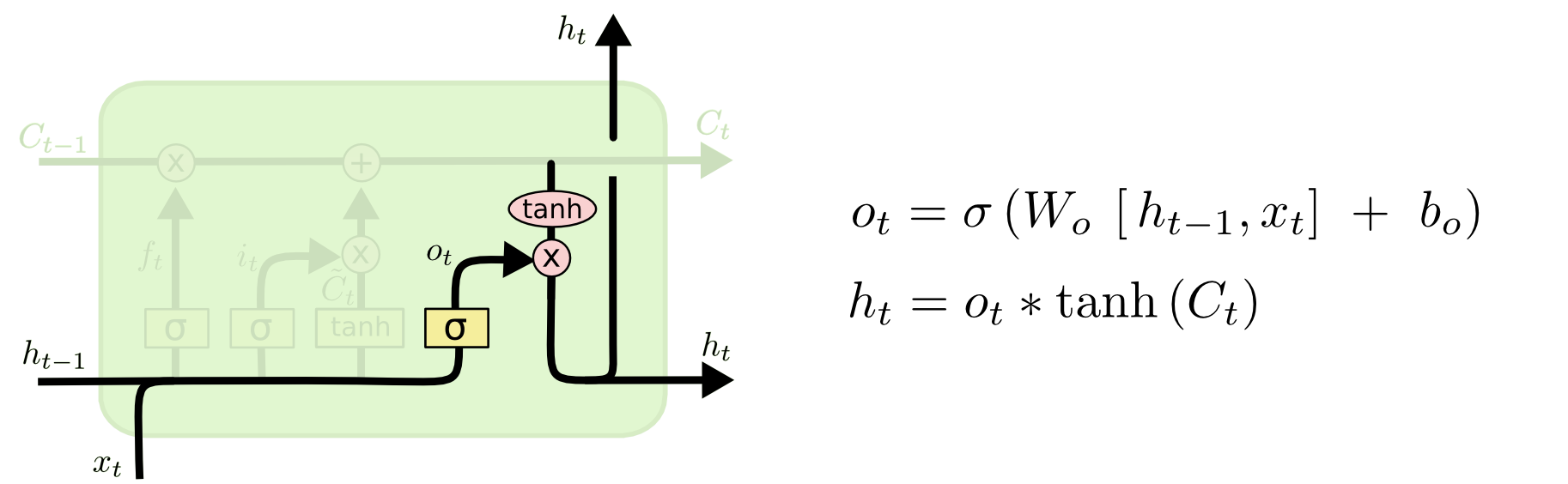
记忆仓库已经更新完毕,现在要从里面取信息。这个时候输出门就相当于专管出荷的“审核员”,对从仓库中取出来的货物进行“把关”,将经过 Tanh 整合后的 \( {C}_t \) 和 \( o_{t} \) 相乘,得到“审核”后的出荷货物,达成输出的目的。
将 \( {C}_t \) 用 Tanh 函数整合原因,前面已经提到 Tanh 的优势;\( {o}_t \) 和前面的 \( {i}_t \) 、 \( {f}_t \) 一样,由 Sigmoid 生成的门控信号,这里均不再赘述。
由此最基本的 LSTM 模型就学习完毕,三道门让模型能“有选择”地忘记、吸收和输出信息,既能捕捉短期的“新信息”,也能记得“很久以前的重要事件”。
但并非所有 LSTM 都与上述的基本模型相同,有些改进过的模型更受欢迎,比如门控循环单元(GRU)。
门控循环单元(Gated Recurrent Unit)
GRU 是 LSTM 的一种变体,把遗忘门和输入门合并成一个“更新门(Update Gate)”,还把记忆和隐藏状态合并了,没有了输出门,而是增加了“重置门(Reset Gate)”,和更新门一起,一个负责写入,一个负责读取,用起来更简单。

里面只有三个神经网络层,两个 Sigmoid 输出门控信号和一个 Tanh 对信息进行整合。
左边的 \( {r}_t \) 就是重置门控信号了,相当于从记忆里选择性地读取一部分信息,也相当于从仓库里找合格的货物。
\( {r}_t \) 由上一时刻的隐藏层输出 \( h_{t-1} \) 和这一时刻的输入 \( x_{t} \) 共同决定,然后又作用到 \( h_{t-1} \) 上,得到经过审核的货物,加到新来的货物 \( x_{t} \) 上,与新货一起参考。再经过 Tanh 进行整合得到 \( \tilde{h}_t \) 。
\( {z}_t \) 是更新门控信号,同时担当着“清理工”和“审核员”的工作。\( {z}_t \) 送入 (1-) 分支和 \( {h}_{t-1} \) 相乘相当于做了原来的“清理工”遗忘门的工作,最右边和 \( \tilde{h}_t \) 相乘,然后往上走和 \( {h}_{t-1} \) 相加相当于做了输入门“审核员”的工作。
GRU 少了一组门控信号,少了一层神经网络,参数更少,计算量也更小,在某些数据集和任务上,GRU 的性能和 LSTM 相当,但训练速度更快,可能在对极其长期的复杂依赖建模上弱于 LSTM。
RNN / LSTM / GRU 比较
结构复杂程度(计算复杂度 / 参数量 / 资源消耗): LSTM > GRU > RNN
长期依赖建模性能比较:LSTM ≈ GRU > RNN
至于三者的联系,GRU 是 LSTM 的变体,更易用,LSTM 是 RNN 的改良版本,为解决 RNN 的梯度衰减问题而设计。
现在主要都在用 LSTM 和它的变体,性能确实没得说。
学习完基础的时序模型,下一节就是经典的注意力机制了。
不规范的参考出处:
[1] 史上最详细循环神经网络讲解(RNN/LSTM/GRU) – 知乎
[2] https://colah.github.io/posts/2015-08-Understanding-LSTMs/
下一篇:从 0 开始的 Transformer 梳理(3)注意力机制与 Transformer 原理