普通注意力机制的原理
人的注意力往往集中在视线的正中间,专注于那一小部分重要的内容。模型怎么去注意到那些重要的内容呢?我们喂给模型的数据是一个个矩阵或张量,要想让模型重点关注到某些信息,一个直观的想法就是让这些地方的数值变得更大。注意力机制就是这样一个过程,通过加权求和的方法,赋予不同的输入元素以不同的权重,重要的信息权重大,重点关注,不重要的信息权重小,被忽略。
注意力机制里有 键 Key、值 Value 和 查询 Query,直接看这三个东西会比较抽象,所以我用一个例子来打比方。
假设我们半夜回家,家里乌漆嘛黑的,而我们手里有手电筒,用手电筒扫来扫去地找要换的鞋。
家里会有很多柜子(Key),柜子里会放有一些东西(Value),而我们要换鞋,就得去查一下,哪个地方更有可能会放着鞋呢?我们的鞋就是 Query 了。
你可能会想,鞋柜呀,因为鞋不都是放鞋柜里的嘛!当我们在脑补这个想法的时候,就开始在做类似于“相似度匹配”的事情了,鞋和鞋柜之间比鞋和床头柜或者其他家具之间有着更高的匹配度。
然后我们把手电筒打开,手电筒把光束聚焦到最有希望的位置——手电筒的光束就相当于权重,也就是注·意·力。你会把注意力集中在手电筒照亮的地方(权重大),而不会去看暗的地方(权重小)。
最后我们照亮并打开了鞋柜,在里面去提取我们真正需要的 Value (鞋),这就是注意力机制的原理。
Attention 机制最早是在计算机视觉里应用的,随后在 NLP 领域也开始应用了,真正发扬光大是在 NLP 领域,因为 2018 年 BERT 和 GPT 的效果出奇的好,进而走红。而 Transformer 和 Attention 这些核心开始被大家重点关注。[1]
如果用图来表达 Attention 的位置大致是下面的样子:

注意力原理的三步分解
分为三个阶段:
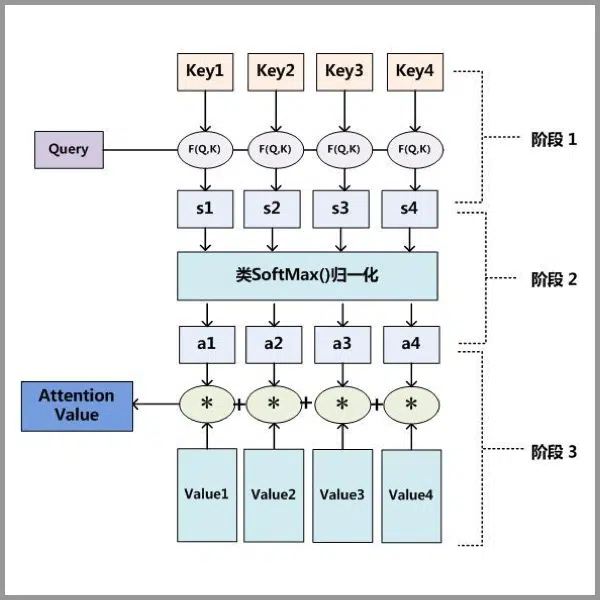
因为是普通的注意力机制,所以先不去管 Query、Key、Value 是怎么来的,我们直接给定。
第一步: Query 和 Key 进行相似度得分计算,得到权值
第二步:将权值进行归一化,得到直接可用的权重
第三步:将权重和 Value 进行加权求和(矩阵相乘)
之前找鞋的例子里我们的权重就是 1 (亮的地方)和 0(暗的地方),这里权重是 0~1 之间的小数了,所以是加权求和。这三步用一个公式来表示就是:\(\)
$$ \mathrm{Attention}(Q,K,V)=f_{归一化} \left( \mathrm{score} (Q,K) \right) V $$
有了注意力机制后,模型就从过去的死记硬背阶段转为了融会贯通阶段,让模型的性能连上好几个高度。
代表性的注意力机制模型
上一节里的 \(\mathrm{score}(\cdot)\) 只是一个笼统的写法,因为它本身有很多种变体,具有代表性的相似度得分计算方式有如下几种。
Bahdanau Attention(加性注意力)
$$ \mathrm{score} (s_{t-1},h_i) = v_{a}^{T} \mathrm{Tanh} \left( W_as_{t-1} + U_ah_i \right) $$
这个注意力里用了一层前馈神经网络,而且该注意力需要结合 encoder 和 decoder 考虑,接受上一个 decoder 的输出 \( s_{t-1} \) 和当前 encoder 的输出 \( h_{t} \),激活函数是 Tanh,再与可学习的向量 \(v\) 做点乘。
Luong Attention(点积注意力)
直接点积:
$$ \mathrm{score} (q,k) = q^Tk $$
带缩放的点积:
$$ \mathrm{score} (q,k) =\frac {qk^T} {\sqrt{d_k}} $$
缩放点积是 Transformer 采用的注意力,里面的 \(d_k\) 为 \(K\) 的维度,相当于归一化操作,防止梯度消失或爆炸。
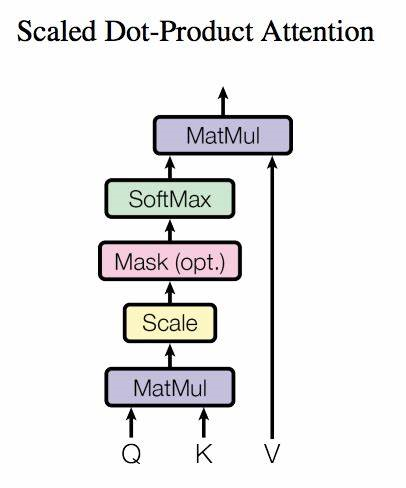
带缩放的点积注意力(Scaled Dot-Product Attention)有时会在尺度缩放(Scale)和归一化(Softmax)操作之间添加一个 Mask 操作,用来屏蔽一部分注意力,Mask 在需要屏蔽的位置取 -∞(很大的负数),softmax 之后的权重就会变为 0,不参与加权求和。
Padding Mask 将不同长度的序列对齐为相同长度(比如不同的句子有不同的长度);
Look-Ahead Mask 屏蔽当前时间步之后的信息,且只在 Decoder 端进行,比如在生成句子时保证预测第 t 个词时不能偷看 t + 1、t + 2… 的词,只能依赖过去的词。
注意力机制变种
软注意力与硬注意力(Soft and Hard Attention)
上面找鞋的例子即硬注意力的原理:选择注意力分数最高的 value,而软注意力是对所有 value 加权求和。
硬注意力的好处就是每一步都明确地“指向”某一个输入位置,很容易可视化对齐结果,但坏处就是不能反向传播了(离散取值,不可微),得用其他的方法进行梯度估计(强化学习或蒙特卡罗方法,待学习)。
自注意力(Self-Attention)
即注意自身上下文关联的机制,Query、Key、Value 都来自同一个输入序列 \( X \)。参照上面 Scaled Dot-Product Attention 的图,自注意力的表达式可以写为:
$$ \mathrm{SelfAttention}(X) = \mathrm{softmax} \left ( \frac {XW_Q X W_K} {\sqrt{d_k}} \right ) XW_V $$
Transformer 中用到的就是这一款注意力。
交叉注意力(Cross‑Attention)
和自注意力几乎一致,就是 Query 来自序列 A,而 Key-Value 来自序列 B,模型在对序列 A 中的每个元素做注意力计算时,会抬头去看序列 B,从中挑选与当前查询最相关的信息,再把挑选到的信息(加权后的 V)反馈给序列 A。参考自注意力,交叉注意力的表达式可以写为:
$$ \mathrm{CrossAttention}(Q_A, K_B, V_B) = \mathrm{softmax} \left ( \frac {Q_A K_{B}^{T}} {\sqrt{d_k}} \right ) V_B $$
Transformer 中也用到了这款注意力。
多头注意力(Multi-Head Attention)
将注意力机制并行地多次执行,即有多个注意力头,再将结果拼接融合。如下图所示。
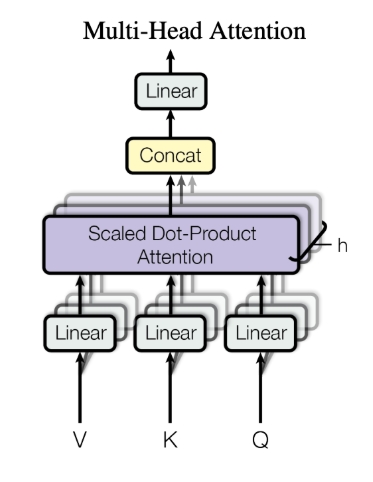
多头注意力和自注意力经常一起用,变成强力的多头自注意力机制(Transformer 中也用到了这款注意力)。
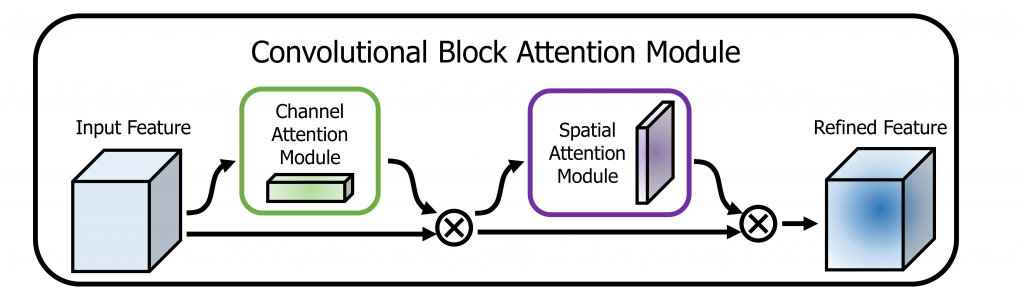
通道注意力(Channel Attention)
通道可以从简单的一张图片开始理解,一张彩色图片分为 R、G、B 三个颜色通道,可以想象成三片彩色塑料片叠在一起。通道注意力就是在调节每个塑料片的透明度,它的经典实现出自 SE-Net(Squeeze-and-Excitation Networks)中。
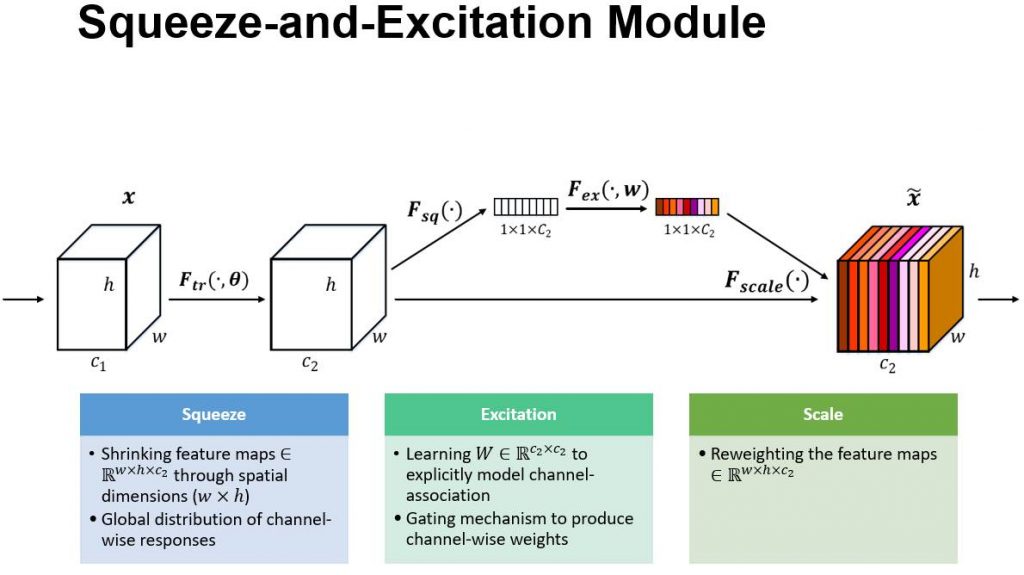
如上图所示,有两个分支,上部的分支就是通道注意力分支。模型先看看整张图里,每一种通道对任务有多重要,再把重要通道”透明度”调大,不重要的通道”透明度”调小。具体的实现分为三步,即 Squeeze 、 Excitation 和 Scale。
Squeeze 步骤 \( F_{sq}(\cdot) \) 会对每个通道的 \( w \times h \) 维特征图做全局平均池化(全部求和再取平均)。Excitation 步骤 \( F_{ex}(\cdot, w) \) 为两层 FC + ReLU + sigmoid,输出权重向量。Scale 步骤 \( F_{scale}(\cdot) \) 做注意力得分加权的操作,达到调整每个通道重要性的目的。
空间注意力(Spatial Attention)
还是那一叠彩色塑料片,空间注意力相当于给整叠塑料片盖上一张半透明的贴纸,它的经典实现出自 CBAM(Convolutional Block Attention Module)。假设原输入特征 \( F \) 已经经过了通道注意力机制模块得到 \( F‘ \)
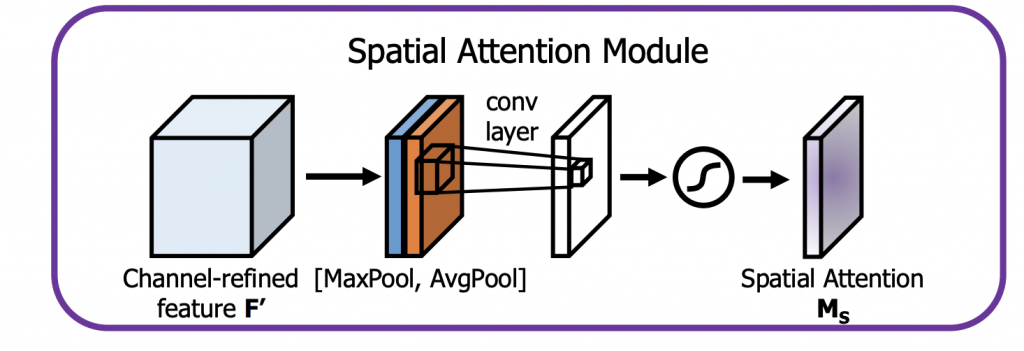
如上图所示,先对输入 \( F‘ \) 在通道维度做最大池化(MaxPool)和平均池化(AvgPool),沿通道维度拼接,再用大小为 7×7 的卷积核进行卷积,最后经过激活函数,得到注意力图 \( M_s \)。这个注意力图会告诉模型,特征图里的哪些地方最有用,贴纸的这些地方透明度调大,其他地方透明度调小。
池化的英文为”Pooling”,本意为”池塘“或”汇集“。池化的名字和其作用相对应,把一大滩水”汇集到一个小池凼子里“→把局部特征汇总成一个代表值。
其他注意力机制(待续)
双重注意力(Dual Attention)、可变形注意力(Deformable Attention)、层次注意力(Hierarchical Attention)……等,针对不同任务的不同注意力机制。
Attention Is All You Need
到了最终的学习目标:Transformer 架构。和论文《Attention Is All You Need》中的顺序一样,按照 Encoder stacks、Decoder stacks、Input/Output Embeddings、Positional Encoding 的顺序进行学习。
Transformer 的整体架构
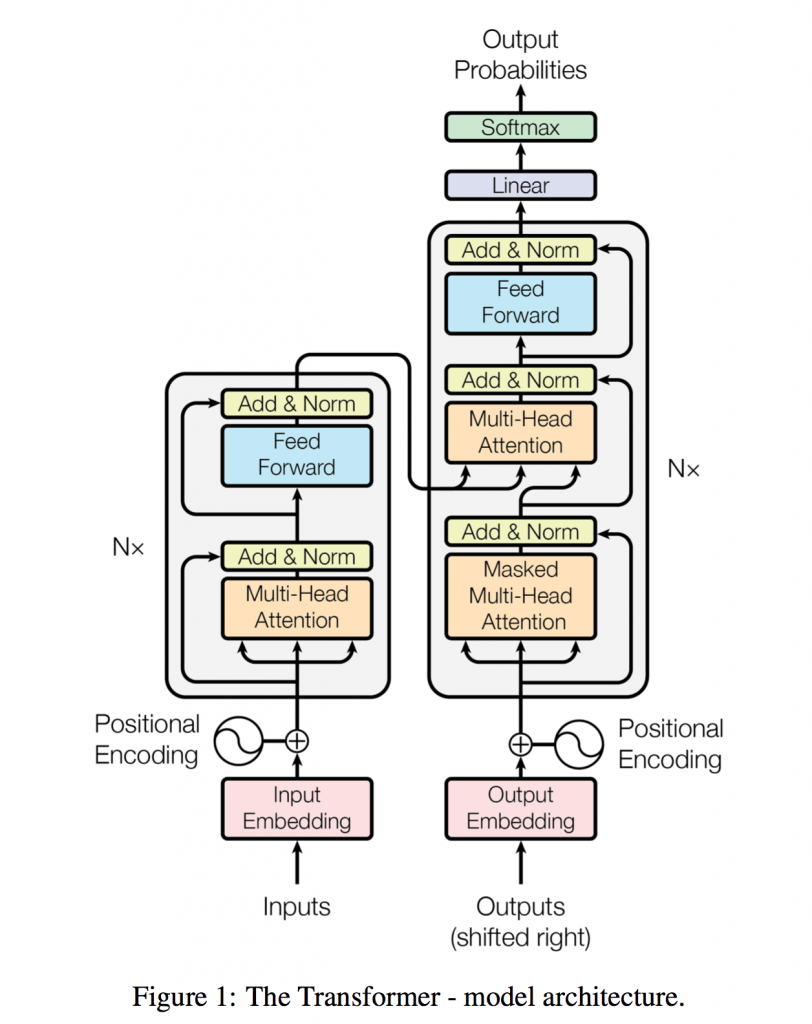
Encoder Stacks
在 Transformer 里,encoder 由六个相似的 stack 堆叠而成。单个 stack 结构是模型框架左侧较矮的灰色圆角矩阵框住的部分。就像乐高积木一样,从下往上的四个积木块可以归纳为:
$$ 多头自注意力 \to 残差归一化 \to 前馈 \to 残差归一化 $$
多头自注意力(Multi-Head Attention)
假如说 h = 8(有 8 个并行的注意力头),输入的 Q、K、V 维度是 \( [B, L, D] \),暂时不管 Batch Size \( B \),Q、K、V 会在 \( D \) 维度切成等长的 8 小段,得到 8 组输入,并行输入到多头自注意力模块中,得到 8 个头的输出,再拼接起来就得到多头自注意力的总输出,捕获了序列的上下文依赖。
$$ \mathrm{Attention}(Q,K,V)=\mathrm{softmax} \left ( \frac {QK^T} {\sqrt{d_k}} \right ) V $$
这个是 Transformer 中的经典注意力表达式,里面的 \(d_k\) 为 \(K\) 的维度,相当于归一化操作,防止梯度消失或爆炸。softmax 就是激活函数了,将权重归一化到 0~1 范围内,而且总和是 1。
残差连接和层归一化(Add & Norm)
将一个子层 Sub-layer 的输出再和输入相加,并经过层归一化处理。表达式:
$$ \mathrm{LayerNorm}(x + \mathrm{Sublayer}(x)) $$
为了利于残差连接和层归一化,作者将模型的输出维度控制在 \( d_{\mathrm{model}} = 512 \)。
残差连接是跳跃连接的一个特定种类,把输入直接“相加”到若干层之后的输出上。
跳跃连接的概念更宽泛,可以是相加(Residual)、拼接(Concat)、门控(Gated skip)、自适应缩放等等。
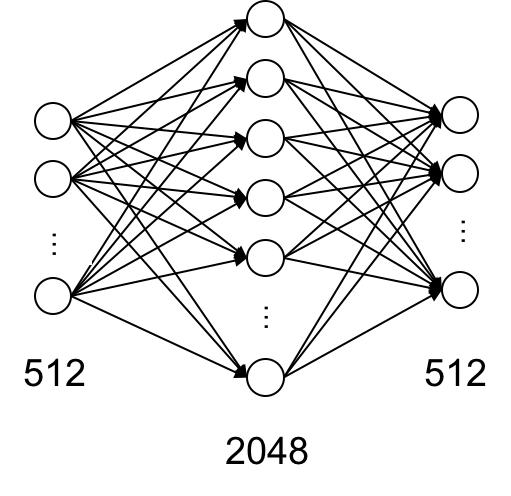
前馈神经网络(Feed Forward Networks)
其实就是多层感知机 MLP,输入层和输出层维度均为 512,隐藏层维度为 2048。
将输入通过 6 个 Encoder stacks 后就得到了编码后的特征,可以送到 Decoder 中,如下图所示。
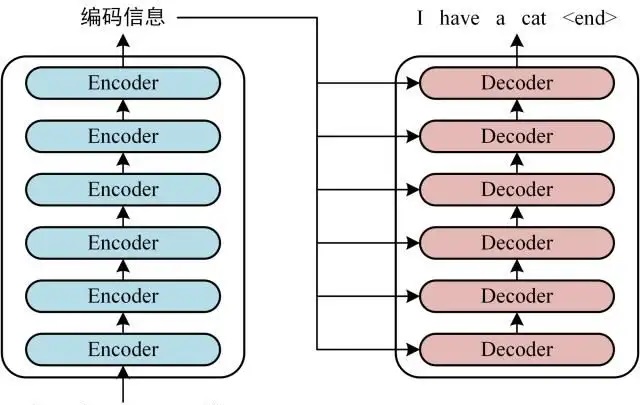
Decoder Stacks
decoder 的单个 stack 结构是模型框架右侧较高的灰色圆角矩阵框住的部分。继续用积木块做比喻,从下往上的六个积木块可以归纳为:
$$ 掩膜多头自注意力 \to 残差归一化 \to 交叉注意力 \to 残差归一化 \to 前馈 \to 残差归一化 $$
其中 Add & Norm、Position‑wise Feed Forward 与 Encoder 一模一样,可以把 Decoder 想成 Encoder 的 2 处升级版。升级过的地方就是下面的两个部分。
带遮挡的多头自注意力(Masked Multi‑Head Self‑Attention)
在前面已经学习过,所加的 Mask 为 Look-Ahead Mask,在表达式中的体现如下:
$$ \mathrm{Attention}(Q,K,V)=\mathrm{softmax} \left ( \frac {QK^T} {\sqrt{d_k}} + M_{\mathrm{casual}} \right ) V $$
其中
$$ M_{\mathrm{casual}} = \begin{cases} 0 &j \le i \\ -∞ &j > i \end{cases}$$
有了 Look-Ahead Mask,模型就不能偷看到未来的信息了,保持自回归特性(限制模型只能用前面的信息预测后面的信息)
交叉注意力(Encoder‑Decoder Cross‑Attention)
在 Transformer 里面 Query 来自前面的 Decoder 层(别忘了 Decoder 是 6 个一样的模块堆叠而成的,上一个decoder 的输出再送入下一个 decoder),而 Key-Value 来自来自 Encoder 的输出。
Input Embeddings
对于输入的词嵌入,目的是将人类看得懂的自然语言转换为机器看得懂的“向量语”,大致的操作分为三步:①查表 → ②缩放 → ③位置编码。
一开始会给模型安排“一本词典”,一个 \(\left | V \right |\)(有多少个词)\(\times d_{\mathrm{model}}\) (每个词的解释,固定长度)的可学习矩阵 \(E\)。①每个词根据自己在句子中的位置 token id \(x_i\) (第一个词就是 0,第二个词就是 1……)查词典,得到词嵌入 \( \mathbf{e}_i \)。②对词嵌入再乘以 \(\sqrt{d_{\mathrm{model}}}\) 稳定方差。③再为词嵌入加一个可学习的位置编码 \( \mathbf{P}_i \),最后得到输入词嵌入:
$$ \tilde{\mathbf{e}}_i = \mathbf{e}_i + \mathbf{P}_i $$
Output Embeddings
从架构图上可以看到,outputs 下方有一个注释:shifted rights,意思是在训练时把真实目标序列 \(<s>,y_1,y_2,…y_{T-1}\) 整体向右移动一位送进解码器,去预测下一个词;推理时每一步把自己刚生成的词再查词典,输送回解码器。
解码器输入跟编码器输入一样,都通过一个可学习的矩阵 \(E\),把 token id 变成 \(d_{\mathrm{model}}\) 维向量,再加位置编码。
预测完毕后,要把隐藏向量(向量语) \(h_t\) 映射回词表(自然语言)进行打分,最自然的做法是再用 \(E^T\) 做一次点积,再加偏置,然后过 soft‑max,这一步就是输出嵌入/LM head。
同一块可学习的矩阵 \(E\) 就相当于一个双向翻译的词典,编码时把 one‑hot -> dense(输入嵌入),解码时把 dense -> vocabulary logits(输出嵌入,转置后使用)
(嵌入这一块已经在Transformer 模型外部了)
Positional Encoding
自注意力机制本身并不能感知到顺序关系,把“猫对我哈气”和“我对猫哈气”里的词向量直接丢进去,注意力只看到 4 个词(猫,我,对,哈气),完全不知道谁先谁后。所以需要给每个词贴一个座标标签,告诉模型“这是第 1 个”“这是第 2 个”……这样它就能分清先来后到。
Transformer 中用到的正弦/余弦位置编码为三角式。对于序列中的第 pos 个位置,绝对位置编码向量的第 k 个维度的值
$$ \begin{align} \mathrm{PE} (pos, 2k) = \mathrm{sin} \left( \frac{pos} {1000^(\frac{2k} {d_{\mathrm{model}}}} \right), \\ \mathrm{PE} (pos, 2k + 1) = \mathrm{cos} \left( \frac{pos} {1000^(\frac{2k} {d_{\mathrm{model}}}} \right) \end{align}$$
下一步学习&回顾…?
BERT?Transformer变种家族?AutoEncoder变种家族?GAN?Diffusion?